
1. 背景介绍
数据量:数千万商户数据
索引数据【检索系统用】大小(15G/大概值)
存储数据【存储系统】大小(50G/大概值)【不包括图片数据,这里的图片仅是图片id,有专门的图片服务存储图片】
访问量:百万PV
机器:32位机器,这个背景很重要,因此每个服务只能用3g内存,否则所有数据放到缓存中就好了
所有的数据都存储在本地文件中,每个服务部署在一台机器,对应一份数据
2. 架构图 
如图所示:最核心的两个系统,一个是检索系统【左边部分】,一个是存储系统【右边部分】。。
那就先说说这两个系统分别是干什么用的。
检索系统:根据传递参数【例如:地址,类别,检索词等返回检索结果列表】,这个列表每条数据包含的信息当然不是每条商户的全部信息,用来【检索用的属性】肯定也不是商户的全部信息,因此检索系统的所使用的数据肯定是从全部数据中导出的有用的数据【提高效率,节省内存】。
存储系统:存储系统存储着全部的商户数据信息,包括图片,点评,商户信息等。当然这些数据的存储有一定的逻辑,方便数据查询和保存。
再说说这两部分的交互吧:定期的将存储系统中的数据导出,为检索系统建需要的索引,供检索系统使用。但是有一个问题,大量的数据,想要建索引,需要的时间很长,因此索引只能定期的更新。而数据是会随时更改的,这部分数据需要实时的被检索到,因此检索系统和存储系统的交互就是为了完成这两个方面。一个是定期的将存储系统的数据导出,建静态索引给检索系统使用,另外一个是将实时改变的数据分发给动态索引服务,建动态索引,保证实时更新的数据能够被检索到。
好吧,到现在该具体介绍下各个系统的各个服务是干什么的啦。
先说说检索系统:index用于静态数据检索,主要的检索逻辑在这里。dindx用于动态数据的检索和加载。sui检索服务的初期处理和后期处理由其来完成【query分析,归并各个检索结果,重查等逻辑】。
再说说存储系统:bds 数据的灌入【增删改】bbts【存储商户信息】bps【点评信息】bui【查询商户信息】
dispatch【数据分发服务】
3. 分布式和同步策略
分布式策略:检索系统:
1. 根据按城市搜索的特性,将数据分割【大城市数据,小城市数据】。
2. 每个内部apache可与若干sui服务通信,每个sui服务可与若干组检索服务通信
(实际情况8组内部apache,4组sui,6组index/dindex,其中两组sui三组index/dindex只检索大城市数据,另外的只检索小城市数据)
存储系统:
1. Bbts/bps两个服务一组,分为若干组,bui服务也分为若干组,每个bui可连接若干组bbts/bps(实际情况3组bbts/bps服务,两组bui服务,其中一组bbts/bps不提供查询服务)
数据同步策略:
1. dispatch和bds服务分别记录同步日志,dispatch服务和bbts和bps服务分别记录同步点和同步日志。Bbts和bps每次重启后都会根据bds同步日志和自己同步点同步数据。
2. 每次数据导出时,会停掉不提供查询服务的(bbts/bps),会同时生成同步点数据文件,那么,在数据导出重建索引后,dindex和index会重启重新加载新的数据索引和相关数据,那么dindex通过dispatch和同步点同步新的数据。
4.服务级别 通用服务结构: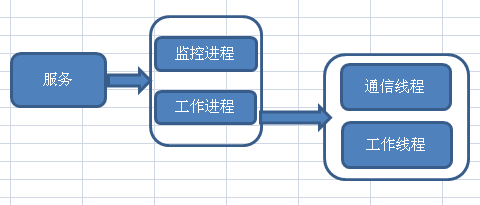
监控进程主要工作:监控工作进程状态,控制工作进程重启
工作进程:真正提供服务的进程。
监控策略:
判断消息队列中待处理数目,若小于一个值,则认为工作进程正常。
根据工作线程数开辟一块共享内存,工作线程会更新对应状态,若消息队列中,待处理数大于某个值,且有线程上次状态更新时间和当前时间小于某个值,则认为工作进程正常。
否则的话发送信号,控制工作进程状态。
服务间通信:
ACE
统一的package格式,key:value
加速:
Sui缓存
Index为二级索引做了缓存
5.未完待续:
存储系统数据和同步日志存储的结构和
索引结构
sui TaskBoard设计
图片存储结构